AIで論文を読む: Brain-to-Text Decoding
Meta が発表した脳波から文章を解読する論文を Gemini Paper Summarizer で要約して、図や表を手動で追加しました。
参考
【注意】AI の説明には誤りが含まれる可能性があり、正確さは保証できません。詳細は原論文を確認してください。
目次
タイトル
脳からテキストへのデコード:タイピングによる非侵襲的アプローチ
Abstract
現代の神経義肢は、発話や運動能力を失った患者のコミュニケーションを回復させることができる。しかし、これらの侵襲的なデバイスは、脳神経外科に固有のリスクを伴う。本研究では、脳活動から文章の生成をデコードする非侵襲的な手法を紹介し、35人の健康なボランティアの集団でその有効性を示す。そのために、参加者がQWERTYキーボードで短く記憶した文章を入力している間に、脳波(EEG)または脳磁図(MEG)から文章をデコードするように訓練された新しい深層学習アーキテクチャであるBrain2Qwertyを提示する。MEGでは、Brain2Qwertyは平均して32%の文字誤り率(CER)に達し、EEG(CER:67%)を大幅に上回る。最高の参加者では、モデルは19%のCERを達成し、トレーニングセット外のさまざまな文章を完全にデコードできる。エラー分析は、デコードが運動プロセスに依存していることを示唆しているが、タイプミス分析は、高次の認知因子も関与していることを示唆している。全体として、これらの結果は、侵襲的および非侵襲的な方法の間のギャップを狭め、コミュニケーションをとれない患者のための安全なブレイン・コンピュータ・インタフェースを開発する道を開く。
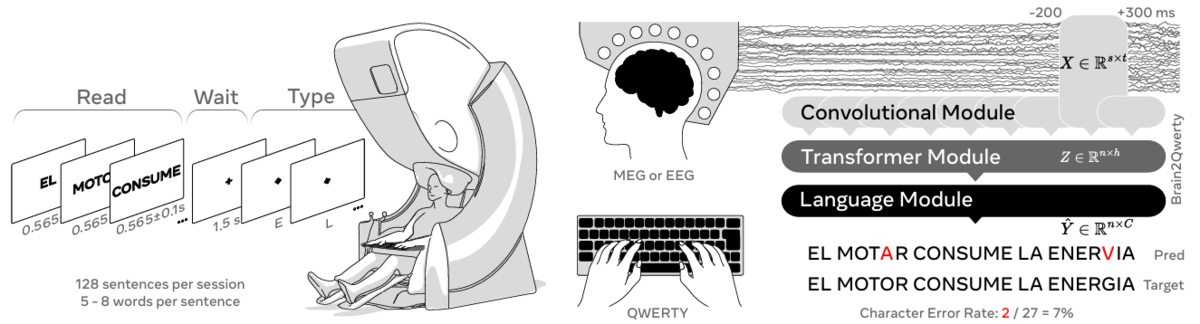
35人の被験者から、脳波測定(EEG)と脳磁図(MEG)を用いて記録した。文章は単語ごとに画面に表示された。最後の単語の後に、視覚的な手がかりが示され、視覚的なフィードバックなしで、この文章のタイピングを開始するよう促された。Brain2Qwertyモデルには、脳活動からテキストを解読するための3つのコアステージが含まれている。 図1 手法
(1) 畳み込みモジュール(M/EEG信号の500ミリ秒のウィンドウを入力とする)
(2) 文レベルで訓練された変換モジュール
(3) 変換モジュールの出力を修正する事前学習言語モデル
性能は、文レベルの文字誤り率(CER)を用いて評価される。 脳がタイピングを行う仕組みの分析は、関連論文(Zhang et al., 2025)に記載されている。
概要
本論文では、脳波または脳磁波から文章を解読する深層学習アーキテクチャBrain2Qwertyを提案し、非侵襲的な脳-テキスト変換の可能性を示す。
問題意識
本論文は、話すことや動くことができなくなった患者のコミュニケーションを回復させるための、非侵襲的な脳-テキスト変換(Brain-to-Text)手法を提案している。具体的には、脳波(EEG)または脳磁波(MEG)を用いて脳活動を記録し、それに基づいて文章を解読する新しい深層学習アーキテクチャBrain2Qwertyを導入し、その有効性を検証している。
手法
本論文では、脳波(EEG)または脳磁波(MEG)から文章を解読するための新しい深層学習アーキテクチャであるBrain2Qwertyを提案する。Brain2Qwertyは、参加者がQWERTYキーボードで文章を入力している間の脳活動を記録し、その脳活動から文章を解読する。
新規性
本論文では、脳波(EEG)または脳磁図(MEG)を用いて、人がQWERTYキーボードで文章を入力する際の脳活動から、非侵襲的にテキストをデコードする新しい手法であるBrain2Qwertyが提案されている。この手法は、侵襲的な脳コンピュータインターフェース(BCI)に匹敵する性能を、より安全な非侵襲的な方法で実現する可能性を示唆している点が新規である。特に、MEGを用いた場合、Brain2Qwertyは平均で32%の文字誤り率(CER)を達成し、一部の参加者では19%という低いCERを達成している。また、このモデルは、運動プロセスだけでなく、高次の認知要因もデコードに影響を与えることを示唆している。
章構成
- 1 Introduction
- 2 Results
- 2.1 Linear Decoding
- 2.2 Brain2Qwerty Performance
- 2.3 Comparing Brain2Qwerty to Baseline Models
- 2.4 Brain2Qwerty Ablations
- 2.5 Analyses of Decoded Sentences
- 2.6 Impact of Word Type and Frequency
- 2.7 Impact of Keyboard Layout
- 2.8 Impact of Typing Errors
- 3 Discussion
- 4 Methods
- 4.1 Experimental Protocol
- 4.2 Decoder
- 4.2.1 Architecture
- 4.2.2 Training
- 4.2.3 Evaluation
- 4.2.4 Model comparison
- 5 Acknowledgments
- References
1 Introduction
脳損傷により発話能力を失った患者に対する脳コンピュータインターフェース(BCI)の研究は急速に進展している。脳の運動野に埋め込まれた頭蓋内デバイスは、ニューラル活動を記録・解読し、運動やコミュニケーションを支援する。当初は言語機能の解読に限定されていたが、AIモデルの発展により、自然言語生成に近い速度で脳からテキストを解読できるようになった。しかし、侵襲的な神経補綴具は脳出血や感染症のリスクがあり、長期的な機能維持も課題である。非侵襲的なBCIはこれらの課題を解決する可能性があるが、脳波(EEG)は信号対雑音比が低く、複雑なタスクが必要となる。脳磁図(MEG)はEEGよりも信号対雑音比が高く、言語理解パラダイムにおけるMEG信号からの自然言語再構築において、AIモデルが大きな改善を示している。本研究では、非侵襲的な脳活動記録からテキスト生成を解読するAIモデルBrain2Qwertyを紹介する。
2 Results
2.1 線形復号
タイピングプロトコルが期待される脳反応を引き起こすことを検証するために、まず、左右の手によるキー押下によって誘発される反応の違いに焦点を当てる。得られた地形は、皮質の運動活動に関連するものとして典型的である。さらに、キー押下からの各タイムサンプルで、左右の手の反応を分類するために、被験者ごとに線形リッジ分類器を訓練した。ホールドアウトの復号化は、キー押下後$t=40$ミリ秒でピークに達する。MEGは、被験者全体で74±1.3%(標準誤差)の手の分類精度を達成し、EEGよりも16%優れている(Mann Withney $p$: $10^{-7}$)。次に、この線形分類を文字レベルで繰り返した。文字の復号化はほぼ同じ時間にピークに達し、MEGでは22±0.8%、EEGでは16±0.5%の性能である。全体として、これらの結果は、本プロトコルが期待される脳反応につながることを確認している。
A. 左手と右手のキー押し下げによる誘発電位反応の違い。各黒線は、キー押し下げに対するセンサの差分電圧を表す。 図2 モデル間のデコーディング性能
B. Aと同じだが、MEGによる結果。
C. 線形分類器は、各キーの押下に対して左手と右手を予測するように、各時間サンプルで訓練される。 灰色の線は偶然のレベルを表し、エラーバーは参加者全体の平均の標準誤差である。 重要なデコーディングスコア(p <0.05)は星印で示されている。
D. C.と同じだが、文字分類用である。
E-H. 既存のアーキテクチャ(線形およびEEGNet)と、3段階のBrain2Qwertyモデル(Conv+Trans+Language Model)の比較(HERとCERの両方)。
各点は、1人の参加者の平均スコアを表す。統計的有意性は、p < 0.05 ()、p < 0.01 ()、p < 0.001 ()で表される。
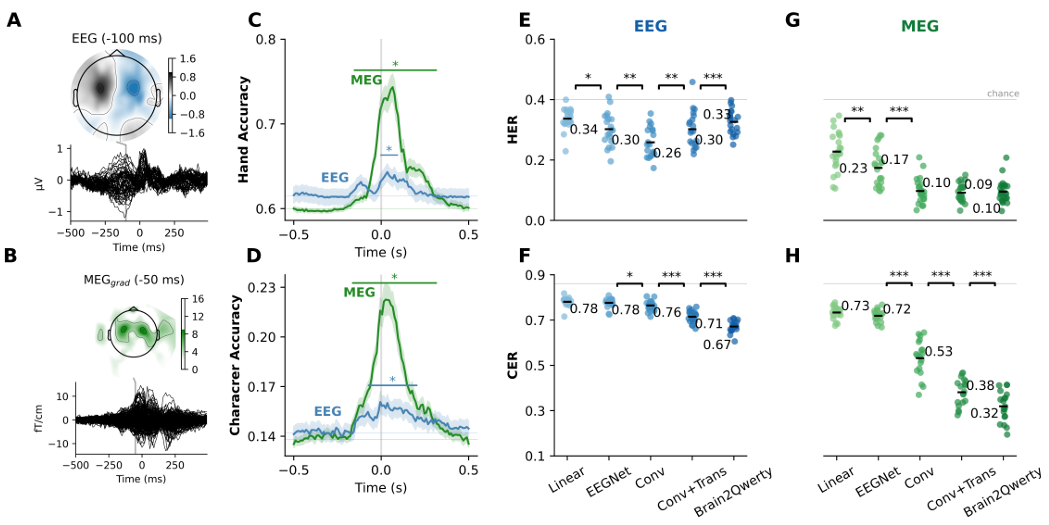
2.2 Brain2Qwertyの性能
次に、Brain2Qwerty(新しい深層学習アーキテクチャ)を訓練し、これらのM/EEG信号から個々の文字を復号化し、手の誤り率(HER)と文字の誤り率(CER)の両方を評価した。その結果、Brain2QwertyはMEGで32±0.6%、EEGで67±1.5%のCERを達成した。この性能は、記録デバイス間で大きな差があることを反映している($p<10^{-8}$)。EEGの最悪および最高の被験者は、文全体でそれぞれ61±2.0%および71±2.3%のCERに達した。同様に、MEGの最高および最低の被験者は、それぞれ19±1.1%および45±1.2%のCERに達した。
2.3 Brain2Qwertyとベースラインモデルの比較
Brain2Qwertyは、従来のベースラインアーキテクチャと比較してどのように機能するのか?この問題に対処するために、線形モデルとEEGNet(BCIで一般的に使用されるアーキテクチャ)を同じアプローチで訓練し、それらの復号化性能をBrain2Qwertyと比較した(被験者間でWilcoxon検定を使用)。EEGNetは、MEGのHER($p=0.008$)とCER($p<10^{-4}$)の両方で線形モデルよりも優れているが、EEGのHERでのみ優れている($p=0.03$)。ただし、EEGNetはモデルほど効果的ではなく、EEGではCERで1.14倍($p<10^{-5}$)、MEGでは2.25倍($p<10^{-6}$)の改善を達成している。
2.4 Brain2Qwertyのアブレーション
設計上の選択を検証するために、モデルのさまざまなアブレーションバージョンを再訓練した。具体的には、同じハイパーパラメータで(i)畳み込みモジュール(つまり、トランスフォーマー、言語モデルなし)、および(ii)Conv+Transformer(つまり、言語モデルなし)を再訓練および評価した。畳み込みモジュールのみが、EEGのHER($p=0.009$)とCER($p=0.03$)の両方、およびMEGデータ(HER:$p<10^{-5}$、CER:$p<10^{-6}$)でEEGNetよりも優れている。トランスフォーマーの追加は、EEG($p<10^{-4}$)とMEG($p<10^{-6}$)の両方でCERにのみ有益であるように見える。最後に、言語モデルモジュールの使用により、EEG($p<10^{-5}$)およびMEG($p<10^{-6}$)のCERがそれぞれ4%および6%改善される。全体として、これらの結果は、トランスフォーマーによって提供される文レベルの文脈化が、自然言語の統計的規則性を活用することと相まって、個々の文字の復号化を効果的に改善することを示している。
正しい文字は青字で、間違いは赤字で、タイプミスは下線で表示されている。正しいスペースと間違ったスペースはここでは視覚化されていないことに注意。 表1 EEG(左)とMEG(右)データにおける、被験者間でうまくデコードされた文章の例

A. 3人の代表的な被験者の文字エラー率。各点はそれぞれ異なる文を表し、エラーバーは繰り返しにおける平均の標準誤差を示す。白い点は、以下に表示されている文に対応する。 図3 ベスト、中央値、ワーストのMEG被験者の文レベルのパフォーマンス
B. 2つの文の予測復号。文をまたいだ予測を得るために、複数の分割シードが使用された。
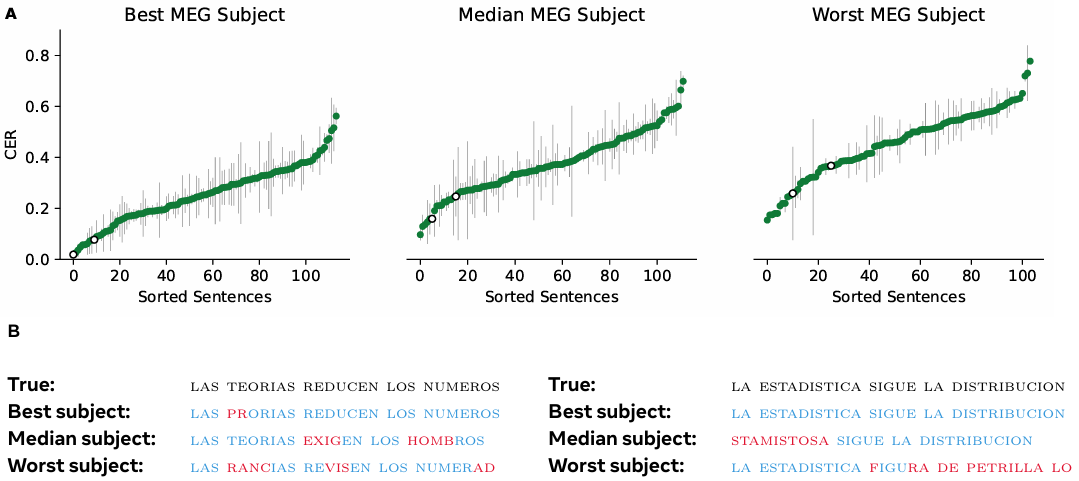
2.5 復号化された文の分析
MEGで記録された3人の代表的な参加者のすべての文のCERと、これらの被験者からの2つの例文を図3に示す。より多くの復号化例は、MEGでいくつかの文が完全に復号化できることを示している(表1、右)。興味深いことに、これらの例のいくつかでは、Brain2Qwertyの言語モデルが参加者のタイプミスを修正できることが示されている。たとえば、EL BENEFICIO SUPERA LOS RIESGOSは、参加者がEK BENEFUCUI SYOERA KIS RUESGISと入力したにもかかわらず、完全に復号化された。
表2 MEGデータの各切除における復号化された文章の例。表1と同じ色分け。

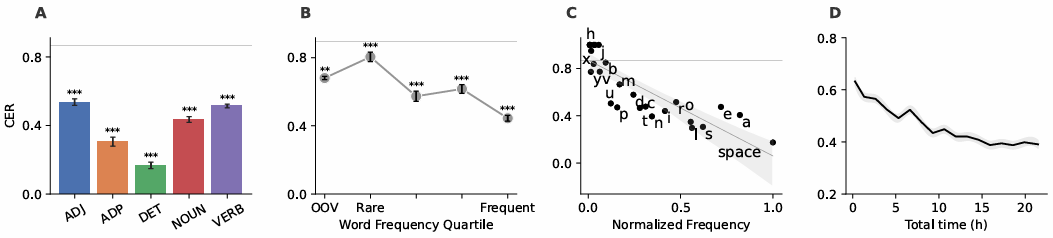
2.6 単語の種類と頻度の影響
Brain2Qwertyが単語の種類に関係なく単語を復号化するかどうかをテストするために、品詞(POS)カテゴリごとにCERを個別に評価した(図4A)。すべてのPOSカテゴリは、限定詞を除いて有意に復号化されており、非常に低いCER(17±1.9%)を示した。この現象は、2つの要因による可能性がある。短い長さと高い頻度。この仮説を正式にテストするために、最初に単語の頻度がCERに与える影響を分析した(図4B)。その結果、頻繁な単語はまれな単語よりも適切に復号化されることが確認された($p=10^{-7}$)。興味深いことに、トレーニングセットにない単語(語彙外、OOV)も、比較的悪いCER(68±2.1%)で復号化できることを確認した。トレーニング/検証/テスト分割のランダムなパーティションでは、OOVワードはまれなワードになる傾向があるため、これは当然の結果である。
次に、各文字の頻度が復号化にも影響するかどうかを評価した。その結果、文字の頻度と復号化の精度との間に有意な相関関係が見られた:$R=0.85$、$p < 10^{-8}$(図4C)。スペイン語の「z」、「k」、および「w」などのまれな文字は、チャンスレベルを超えて復号化されないが、文中の文字の0.08%、0.08%、および0.05%しか占めていない。これらの結果は、トレーニング中に発生する反復回数(単語と文字)がパフォーマンスに直接影響することを示唆している。
これを検証するために、トレーニングセットの均一にサンプリングされたサブセットでモデルを再トレーニングした(図4D)。その結果、CERはトレーニングデータの量に応じて減少することが示された:$R=0.93$、$p<10^{-7}$。
ここで示した結果は、Conv+Transモデルを使用して処理したMEGデータに特有のものである。 図4 文字レベルおよび単語レベルのパフォーマンスの分析
A. 文字誤り率(CER)は、形容詞(ADJ)、名詞、動詞、限定詞(DET)、および前置詞(ADP)のパフォーマンスがどのように変化するかを評価するために、さまざまな品詞カテゴリーにわたって評価される。
B. 単語頻度を関数とするCER。訓練データに含まれない単語のデコーディング(復号)を Brain2Qwerty が実行できるかどうかをテストするために、語彙外(OOV)デコーディングが使用される。
C. 文字頻度を関数とする CER。
D. 訓練データに含まれる記録時間の関数としての CER。
2.7 キーボードレイアウトの影響
Brain2Qwertyが(言語の非様相表現とは対照的に)運動皮質からの脳活動に依存している場合、その復号化エラーはQWERTYキーボードの特定のレイアウトに関連すると予想される。この仮説をテストするために、復号化されたキー押下と実際のキー押下との間のキーボード距離を分析することにより、誤って予測された文字の混同パターンを評価した。その結果、物理的な距離と混同率との間に強いピアソンの相関関係が見られた:$R=0.73$、$p=0.02$(図5A)。この分析を補完するために、scikit-learnのK-meansクラスタリングアルゴリズムを使用して、畳み込みモジュールの最後のレイヤーの埋め込みのクラスタリング分析をさらに実行した。2つのクラスターでトレーニングすると、この教師なし分析により、左手と右手のキーが完全に分離される。最大10個のクラスターを使用すると、結果のパーティションはキーボードレイアウトと一貫性が保たれる(図4B-E)。これは、キーボードの空間レイアウトがモデルによって学習された高次元表現で適切にエンコードされていることを示している。全体として、これらの結果は、デコーダーのエラーがQWERTYキーボード上のターゲット文字に物理的に近いキーと混同される傾向があることを示しており、デコーダーが主に運動表現に依存していることを示唆している。
提示された結果は、Conv+Transモデルを使用して処理されたMEGデータに特有のものである。 図5 キーボードのレイアウトとタイピングエラーの影響
A. キーボードの距離効果。 混同率は正規化されたキーボードの距離に対して分析される。
B. クラスタリング分析。 モデル埋め込みのK平均法によるクラスタリング(それぞれ2個(上)と10個(下)のクラスタ)。
C. キー押下間隔分析。正しいキーストロークとタイピングエラーのキーストローク間隔の比較。前後の文字の両方に注目している。2つの間隔の合計が表示されている。
D. タイピングミスによるパフォーマンスの違い。Conv+Transモデル(左)とConvモデル(右)を使用した、正しい文字とタイピングエラーのパフォーマンス比較。
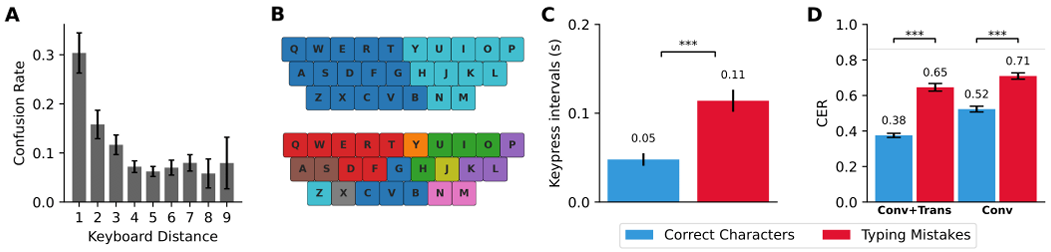
2.8 入力エラーの影響
本プロトコルでは、参加者が間違いを修正することは許可されていない。入力エラーはキー押下の3.9%を占め、文の65%に存在する。さらに、それらは特定の動作に関連付けられている(図5C):文字を入力するのにかかる時間(キー間隔で測定)は、正しく入力された文字(50±7ms)と誤って入力された文字(114±12ms、$p=10^{-7}$)の間で2倍になる。このよく知られた現象(Logan and Crump, 2010)は、おそらくためらいや間違いの監視を反映している。入力エラーが復号化のパフォーマンスに与える影響を評価するために、正しく入力された文字と誤って入力された文字のCERを個別に評価した(図5D)。その結果、Conv+Transモデルでは、正しく入力された文字は、誤って入力された文字よりも優れたCER(38%対65%、$p=10^{-7}$)につながることが示された。ただし、この結果は、トランスフォーマーによって有効になる文の文脈化によって部分的に推進されている可能性がある。このエラー分析に対する文脈の影響を最小限に抑えるために、畳み込みモジュールのパフォーマンスを評価した(図5D、右)。繰り返しますが、正しく入力された文字は、誤って入力された文字(52%対71%、$p=10^{-7}$)よりも優れたCERにつながる。この結果は、運動プロセスが不正確に実行されると、復号化のパフォーマンスが低下することを示唆している。
3 Discussion
本研究は、非侵襲的な脳記録から文章の生成を解読する新しい手法を導入する。MEGを使用した場合、Brain2Qwertyモデルは被験者全体で平均32±0.6%の文字誤り率(CER)を達成し、最もパフォーマンスの高い参加者ではCERが19%にまで低下する。解析の結果、この解読は主に2つの要因から恩恵を受けていることが示唆される。第一に、EEG信号の代わりにMEG信号を使用することで、2倍の改善が見られた。第二に、事前学習済みの文字レベルの言語モデルと組み合わせた深層学習アーキテクチャは、標準的なモデルよりも大幅に優れた性能を発揮する。
本研究は、非侵襲的な記録から自然言語を解読する最近の進歩に直接由来するものである。特に、Défossezらは、MEG信号から自然な音声セグメントの知覚を、最大41%のtop-10精度で解読できることを示した。同様に、Tangらは、知覚された文章の意味をfMRIから解読できることを示した。Brain2Qwertyモデルは、これらのアプローチといくつかの要素を共有しており、特に、被験者層と、事前学習済みの9グラム文字レベルモデルの使用である。しかし、言語の知覚ではなく生成の解読に焦点を当てているため、これらの2つの研究は、下流の臨床応用において限定的である。
非侵襲的な記録からテキスト生成を直接解読する研究は稀である。例えば、CrellらはEEGを用いて10文字のみを解読し、文字誤り率は75.8%であり、29文字でのEEG設定における我々の68%よりも有意に高い。同様に、EEGベースのBCIベンチマークは、信号品質の低さと被験者間のばらつきという制約を強調している。我々のEEGの結果は、これらの観察と一致している。単なるメトリック性能を超えて、我々のアプローチは、P300スペラー、SSVEP、fMRIローカライザーなどの非侵襲的BCIで使用される伝統的なプロトコルよりも効率的である。これらの方法は、歴史的に手作りの信号処理と浅い分類器に依存してきた。対照的に、我々のアプローチは、比較的使いやすいタスクに基づいている。
Brain2Qwertyの解読性能は、非侵襲的BCIと侵襲的BCIのギャップを縮めるものの、このギャップは依然として大きい。特に、音声解読の場合、Metzgerらは、1分あたり79語の速度を達成し、372のユニークな単語を持つデータセットで15.2%のCERを報告した。Willettらは、補正モデルを使用した場合、6%未満のCERと1%未満のオフラインCERで、1分あたり90文字のタイピング速度を示した。どちらのアプローチも、皮質内セットアップに依存し、広範な記録セッションを必要とする。したがって、重要な研究課題は、これらのタスクをMEG実験に合わせてスケールおよび適応させることである。
本手法を臨床応用に適応させる前に、解決すべき課題がいくつか残っている。第一に、我々のモデルはリアルタイムで動作しない。特に、トランスフォーマーと言語モデルは文章レベルで動作するため、出力が生成される前に試行を完了する必要がある。さらに、Brain2Qwertyの入力は、キーストロークに合わせるためにMEGセグメントを必要とする。全体として、筋電図で行われていることや音声認識で行われていることと同様のリアルタイムアーキテクチャは、現在の概念実証をリアルタイムで適用可能にするために必要である。
第二に、我々の研究は、健康な参加者のみで行われ、厳密に教師ありモデルを使用している。トレーニングには、各文字のタイミングとアイデンティティの両方を知る必要がある。この設定は、運動能力をまだ持っている神経変性疾患の患者には適しているかもしれないが、キーボードでタイピングタスクを完全に実行できないロックトイン状態の個人には適用できない。この課題に対処するには、タイピングタスクを想像タスクに適応させるか、参加者全体でロバストな一般化が可能なAIシステムを設計する必要がある。
最後に、MEGはEEGよりも優れているが、本研究で使用されているものを含め、現在のMEGシステムはウェアラブルではない。しかし、これは光ポンピング磁力計(OPM)に基づく新しいMEGセンサーの開発によって解決される可能性がある。
全体として、本研究の結果は、より安全でアクセスしやすい非侵襲的なブレイン-コンピュータ・インターフェースの開発に向けた足がかりとなり、最終的には、コミュニケーション能力を部分的または完全に失った個人にソリューションを提供することにつながる。
4 Methods
本研究では、非侵襲的な脳波記録から言語生成を解読することを目的とする。このために、参加者はキーボードで文章を入力し、その際の脳活動をEEGまたはMEGを用いて記録する。これらの装置はミリ秒レベルで神経活動を測定し、EEGは電場を、MEGは頭皮全体に分布したセンサーから記録された皮質ニューロンによって生成される磁場を検出する。
4.1 実験プロトコル
スペインのバスク認知・脳・言語センター(BCBL)で、35人の健康な成人ボランティアを対象に研究を実施した。参加者は、段ボール箱で覆われたキーボードで聞こえてくる単語を入力する必要があった。タイピング精度が80%以上の参加者を選抜した。脳活動はEEGまたはMEGで記録され、それぞれ0.88±0.02時間および0.93±0.01時間であった。5人の参加者はEEGとMEGの両方のセッションに参加した。参加者はインフォームドコンセントを与え、参加に対して1時間あたり12ユーロの報酬が支払われた。
MEGシステムは、306チャンネル(102個の磁力計と204個の平面グラジオメーター)を備えたMeginシステムであり、サンプリングレートは1 kHz、オンラインハイパスフィルターは0.1 Hz、ローパスフィルターは330 Hzに設定されていた。EEGシステムは、BrainVisionのactiCAP slimで、64チャンネル(61個のEEGチャンネルと3個の眼球チャンネル)を備え、BRAINAMP DCアンプを使用し、サンプリングレートは1 kHz、オンラインハイパスフィルターは0.02 Hzに設定されていた。
各試行は、読み、待ち、入力の3つのステップで構成されていた。まず、文章が画面に提示され、ラピッドシリアルビジュアルプレゼンテーションプロトコル(RSVP)を使用した。各単語は、黒色のフォントで、すべて大文字で、50%の灰色の背景に、465〜665 msのランダムな時間表示された。次に、各文章の最後の単語が消えた後、黒色の固定クロスが1.5秒間画面に表示された。3番目に、固定クロスが消えると、タイピングフェーズが開始された。タイピング中は画面に文字は表示されなかった。ただし、最小限の視覚的フィードバックとして、キーストロークごとに画面中央にある小さな黒い四角が時計回りに10度回転した。各セッションは、それぞれ64文の2つのブロックで構成されていた。各セッションの最初の4文はトレーニング文であり、プロトコルの128個の一意の文とは異なっていた。
4.2 デコーダー
本研究のデコーディングモデルの目標は、M/EEG信号の0.5秒のウィンドウに基づいて各キーストロークを予測することである。
4.2.1 アーキテクチャ
Brain2Qwertyモデルは、3つの連続するモジュールで構成されている(図1)。
Convolutional Module。最初の構成要素は、もともとDéfossezらによって導入された修正された畳み込みモデルである。このモデルは、主に4つの部分で構成されている。最初のコンポーネントは、空間注意メカニズムを採用して、センサーの相対的な位置をエンコードする。2番目のコンポーネントは、サブジェクト固有の線形レイヤーを導入して、サブジェクト間の違いを考慮する。3番目のコンポーネントは、畳み込みニューラルネットワークアーキテクチャであり、カーネルサイズ3と拡張期間3を採用する8つのシーケンシャルブロックで構成され、スキップ接続、ドロップアウト正則化、およびGELUアクティベーション関数を組み込んでいる。最後に、時間次元は、シングルヘッドセルフアテンションレイヤーでプーリングされる。したがって、各ウィンドウ$X \in R^{s \times t}$について、CNNは$z \in R^h$を出力し、$h = 2,048$となる。
Transformer Module。畳み込みモジュールの出力は、その後、トランスフォーマーモジュール(Trans)に入力される。トランスフォーマーの受容野は、一意の文に制限されている:$Z \in R^{n \times h}$。トランスフォーマーは、文脈情報を利用してキーストロークの予測を洗練するために使用され、レイヤーあたり2つのアテンションヘッドを持つ4つのレイヤーで構成され、一貫した入力と出力の次元を維持する。最後に、線形レイヤーは、トランスフォーマーの出力を投影して、各文字$Ý \in R^{n \times C}$のロジットを取得する。
Language Model。最後に、トランスフォーマーの出力Ŷは、自然言語の統計的な規則性を活用するために、言語モデルに入力される。このために、KenLMライブラリ(Heafield、2011)を使用して構築され、スペイン語のWikipediaコーパス(Wikimedia、2005)で事前学習された9グラムの文字レベルモデルを使用した。このライブラリは、プレフィックスツリー構造を採用することで、速度とメモリ効率の両方を最適化する。推論時には、言語モデルに予測された文字のシーケンスが入力され、先行する予測された文字に基づいて、最も可能性の高い次の文字を因果的に予測する。
4.2.2 トレーニング
畳み込みモジュールとトランスフォーマーモジュールは、EEGおよびMEG記録に対して同じハイパーパラメータを使用して、すべての被験者間でエンドツーエンドの方法で、重み付けされていないクロスエントロピー損失で共同でトレーニングされる。これにより、合計約400Mのパラメータ(Convで258M、Transで138M)になる。モデルは、早期停止を使用して、AdamWオプティマイザー(Loshchilov and Hutter、2019)を使用して、バッチサイズ128で100エポックトレーニングされる。OneCycleLRスケジューラ(Smith and Topin、2018)(重み減衰=10-4; pct_start=0.1)を使用し、最初の10エポックで学習率を10-4にウォームアップしてから、線形に減衰させる。トレーニングは、32 GBのメモリを搭載した単一のNVIDIA Tesla V100 Volta GPUで実施された。1つのモデルをトレーニングするための合計実行時間は約12時間である。
4.2.3 評価
Hand Error Rate (HER)。分析の目的で、従来のBCI文献(Yousefi et al。(2017); Hill et al。(2012))との比較のために、最初にHERを検討する。このメトリックは、ターゲット文字と予測文字がキーボードの同じ左/右ハンドスプリットに対応するかどうかを推定する。具体的には、Y、H、およびBの左側のキーは左手カテゴリに割り当てられ、右側のキー(Y、H、およびBを含む)は右手カテゴリに割り当てられる。この評価では、特殊文字、数字、スペースは、参加者が両手を使って入力する可能性があるため除外される。
Character-error-rate (CER)。CERは、予測されたキーストロークのシーケンスをターゲットセンテンスに変換するために必要な単一文字編集の最小数を定量化するレーベンシュタイン距離に基づいている。CERが0の場合は、文字レベルの精度が完璧であることを示す。CERの式は、CER =(s + d + a)/ nであり、s、d、aはそれぞれn文字のセンテンスでの置換、削除、追加を表す。特に明記しない限り、Levenshtein Pythonライブラリを使用してセンテンスレベルでCERを計算し、センテンス全体の平均CERを報告する。
4.2.4 モデル比較
統計。統計比較のために、SciPyパッケージによって提供されるノンパラメトリックテストを使用した(Virtanen et al., 2020)。同じサブジェクト内のモデル間の比較には、Wilcoxonテストを使用した。サブジェクト間の比較(例:EEGとMEG)には、Mann Whitney Uテストを使用した。タイムコースのデコーディングでは、タイムサンプル全体の多重比較に対して、偽発見率(FDR)補正をさらに適用した。
ベースラインモデル。2つのベースラインモデルを検討する。1つ目は、scikit-learnライブラリ(Pedregosa et al., 2011)のRidgeClassifierCV関数を使用して実装された線形モデルであり、各サブジェクトについて、記録の単一タイムサンプルから文字を予測するようにトレーニングされた。正則化パラメータαは、10-2から108までの対数範囲のグリッド検索を使用して、ネストされた交差検証によって選択された。この操作は、文字開始を基準とした-0.5秒から0.5秒の間の各タイムサンプルに対して繰り返された。
2番目のベースラインとして、Brain2Qwertyと同じセットアップを使用するモデル、つまり、すべてのサブジェクトをまとめてトレーニングし、時間次元を縮小するモデルが必要である。BCIで古典的に使用される高度にパラメータ効率の高いモデルであるEEGNet(Lawhern et al., 2018)を使用した。実験では、ドロップアウト率0.3で深度6に構成されたEEGNetをトレーニングした。EEGNetはサブジェクト固有の線形レイヤーを組み込んでいないため、すべてのサブジェクトをまとめてトレーニングするこの特定のセットアップではパフォーマンスが低下する可能性がある。文字間の不均衡を考慮しながらチャンスレベルを計算するために、最も頻繁な文字を常に予測するダミーモデルのパフォーマンスを評価した。
コンパニオンペーパー。コンパニオンペーパー(Zhang et al., 2025)では、脳が言語表現の階層をどのように生成するかを探求している。図1(左)と図2Bは、これら2つの研究で共有されていることに注意されたい。
5 Acknowledgments
本研究の遂行にあたり、多くの方々からご支援を賜った。具体的には、マイテ・カルツァコルタ、マネックス・レテ、ジェシ・ヤコブセン、ダニエル・ニエト、ホネ・イラエタ、アライツ・ガルニカ、ハイオネ・ベンゴエチェア、ナタリア・ロウレリ、ナロア・ミラルレス、エナウト・ゼベリオ、クレイグ・リヒター、アメツ・エスナル、オラツ・アンドネギ、そしてアビシェク・チャルナリアとピエール=ルイ・ゼッシュに、貴重なご助言をいただいた。本研究は、バスク政府のBERC 2022-2025プログラム、およびスペイン国家研究庁のBCBLセベロ・オチョア卓越性認定(CEX2020-001010/AEI/10.13039/501100011033)による資金援助を受けている。また、本研究の一部は、欧州連合のホライズン2020研究・イノベーションプログラムにおけるマリー・スクウォドフスカ=キュリー助成契約No.945304 - Cofund AI4theSciencesのもとで実施された。
References
脳波(EEG)および脳磁図(MEG)を用いた脳コンピュータインターフェース(BCI)の研究に関する参考文献リスト:
- Abiri et al., 2019: EEGベースBCIの包括的レビュー
- Angrick et al., 2019: 3D畳み込みニューラルネットワークによるECoGからの音声合成
- Anumanchipalli et al., 2019: 発話文のニューラルデコーディングからの音声合成
- Baillet, 2017: 脳電気生理学およびイメージングのための脳磁図
- Baranauskas, 2021: 現在の侵襲的BCIの性能を制限するもの
- Bodien et al., 2024: 意識障害における認知運動解離
- Brickwedde et al., 2024: 翻訳神経科学へのOPM-MEGの応用
- Bullard et al., 2020: 完全埋め込み型モジュール式ニューロプロテーゼシステムの将来的なリスク評価
- Card et al., 2024: 正確かつ迅速にキャリブレーション可能な音声ニューロプロテーゼ
- Cheng et al., 2002: 高い転送速度の脳コンピュータインターフェースの設計と実装
- Chevallier et al., 2024: オープンサイエンスのための最大のEEGベースBCI再現性研究
- Chung et al., 2019: ポリマー電極アレイを用いた高密度、長期、多領域電気生理学的記録
- Claassen et al., 2019: 急性脳損傷の無反応患者における脳活動の検出
- Crell et al., 2024: EEGを用いた文字分類のための手の運動学の非侵襲的デコーディング
- Donner et al., 2009: 知覚的意思決定中のヒト運動皮質における選択予測活動の構築
- Défossez et al., 2023: 非侵襲的脳記録からの音声知覚のデコーディング
- Fekete et al., 2023: 透明なニューラルインターフェース:高解像度電気生理学と顕微鏡を同時に使用して無傷のニューロン集団を測定するように設計されたマイクロエンジニアリングマルチモーダルインプラントの課題とソリューション
- Goldenholz et al., 2009: 脳磁図と脳波における皮質ソースの信号対雑音比のマッピング
- Gramfort et al., 2014: MEGおよびEEGデータを処理するためのMNEソフトウェア
- Heafield, 2011: KenLM:より高速で小型の言語モデルクエリ
- Herff et al., 2019: 運動、前運動、および下前頭皮質の脳活動から自然で理解可能な音声を生成
- Hill et al., 2012: ヒトの脳活動からの手のデコーディング:BCI文献のレビュー
- Hochberg et al., 2012: 神経制御ロボットアームを使用した四肢麻痺者のリーチと把握
- Hämäläinen et al., 1993: 脳磁図 - 理論、計測、および作業中のヒトの脳の非侵襲的研究への応用
- Jones, 1972: 用語特異性の統計的解釈とその検索への応用
- Lawhern et al., 2018: EEGベースの脳コンピュータインターフェース用のコンパクトな畳み込みニューラルネットワークであるEEGNet
- Leuthardt et al., 2021: 脳コンピュータインターフェース技術の手術用語とリスクの定義
- Logan and Crump, 2010: 熟練したタイピストにおける権限の認知的錯覚が階層的なエラー検出を明らかにする
- Loshchilov and Hutter, 2019: 分離された重み減衰正則化
- Mak and Wolpaw, 2009: 脳コンピュータインターフェースの臨床応用:現状と将来の見通し
- Marchetti and Priftis, 2014: 筋萎縮性側索硬化症患者のための脳コンピュータインターフェースにおけるp3スペラーの効果:系統的レビューとメタ分析
- Metzger et al., 2023: 音声デコーディングとアバター制御のための高性能ニューロプロテーゼ
- Metzger et al., 2022: 重度の四肢および音声麻痺のある個人における音声ニューロプロテーゼを使用した一般化可能なスペリング
- Moses et al., 2021: 失語症のある麻痺患者における音声のデコーディングのためのニューロプロテーゼ
- Owen et al., 2006a: 植物状態における意識の検出
- Owen et al., 2006b: 植物状態における意識の検出
- Pedregosa et al., 2011: Pythonの機械学習ライブラリscikit-learn
- Pinet and Nozari, 2020: 視覚フィードバックの有無にかかわらずタイピングにおけるモニタリングの電気生理学的相関
- Ratcliff and Metzener, 1988: パターンマッチング:ゲシュタルトアプローチ
- Schofield et al., 2022: 光ポンピング磁力計を使用した量子対応機能神経イメージング:光ポンピング磁力計を使用した脳磁図の理由と方法
- Scotti et al., 2024: MindEye2:被験者共有モデルにより、1時間のデータでfMRIから画像への変換が可能
- Shah and Wakai, 2013: 生体医学アプリケーション向けのコンパクトで高性能な原子磁力計
- Smith and Topin, 2018: スーパーコンバージェンス:大きな学習率を使用したニューラルネットワークの非常に高速なトレーニング
- Tang et al., 2023: 非侵襲的脳記録からの連続言語のセマンティック再構築
- Virtanen et al., 2020: Pythonにおける科学計算のための基本的なアルゴリズムであるScipy 1.0
- Wairagkar et al., 2024: インスタント音声合成ニューロプロテーゼ
- Wikimedia, 2005: Wikimediaダウンロード
- Willett et al., 2021: 手書きによる高性能脳からテキストへのコミュニケーション
- Willett et al., 2023: 高性能音声ニューロプロテーゼ
- Xie et al., 2020: 慢性神経インターフェース技術:柔軟で耐久性のある材料の新たな進歩
- Yasar et al., 2024: 超柔軟な触手電極を使用した複数の脳領域にまたがるニューロンアンサンブルの数ヶ月にわたる追跡
- Yi et al., 2014: 簡単な複合四肢運動イメージング中のEEG振動パターンと認知プロセスの評価
- Yousefi et al., 2017: 畳み込みニューラルネットワークを使用したEEG信号からの手の分類
- Zhang et al., 2025: 思考から行動へ:ニューラルダイナミクスの階層が言語生成をどのようにサポートするか
- Zhou et al., 2024: インプラント可能なニューラルプローブ用のポリマーを介した、技術対応、柔軟、軽量、統合デバイス